I have mentioned before that there are some problems with UTF-8 output in cmd.exe with perl 5.
When I successfully built a perl 6 binary, I was excited to see it produce perfectly good UTF-8 output.
To recap, here is output from perl 5:
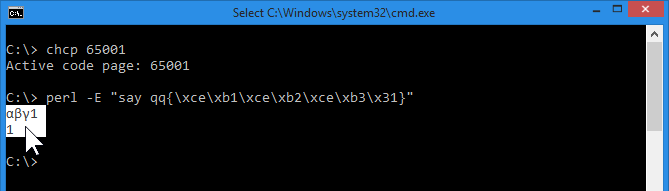
versus output from the perl 6 I built:

I am assuming the problem is obvious: With perl 5, you get some trailing characters repeated.
At first, I thought perl 6 produced correct output was because it was doing “something” “right” for various values of “something” and “right”.
Then, David Farrell reminded me the piping perl 6 output through more results in garbled output:

Of course, piping the output through Cygwin’s less works as expected:

You can guess the source of the difference between perl 6 and perl 5 now:


Yes, perl 6 uses LF instead of CRLF on Windows.
Let’s see what happens if I tack on extra CRs:
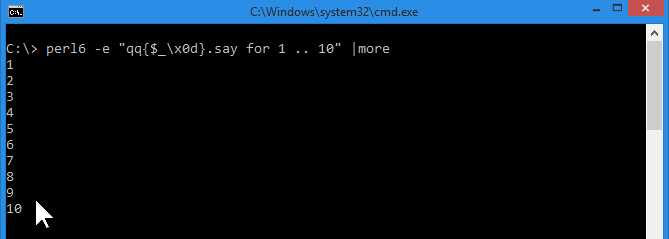
Yup, more now sees a CRLF following each digit, and doesn’t cause garbled output.
Of course, we knew that giving up CRLF translation fixed perl 5 UTF-8 output in cmd.exe.
I am just happy to have figured out the difference between perl 6 and perl 5.
I still have no idea what should be fixed and where — except that I am uncomfortable with what seems to be a “everything is Unix” assumption in perl 6.